Proceedings of the 30th ACM International Conference on Multimedia, October 2022
Speech Fusion to Face: Bridging the Gap Between Human’s Vocal Characteristics and Facial Imaging
Supplementary Material
In the main paper, we present a state-of-the-art algorithm for automatic generation of facial images based on the vocal characteristics extracted from human speech. In this supplementary, we show the input audio that cannot be included in the main paper, additional experiment results, and model details. The input audio can be played in the browser (tested on Chrome and HTML5).
- Open-source code: https://github.com/BAI-Yeqi/SF2F_PyTorch
- Open-source dataset: https://github.com/BAI-Yeqi/HQ-VoxCeleb
Contents
- Teaser
- Qualitative Results
- Data Quality Enhancement
- Additional Experimental Results
- Model Details
- Implementation Details
- References
Teaser
| True face (for reference) |
Face reconstructed from speech |
True face (for reference) |
Face reconstructed from speech |
||
 |
 |
 |
 |
||
| Input speech |
|||||
 |
 |
 |
 |
||
| Input speech |
|||||
 |
 |
 |
 |
||
| Input speech |
|||||
128 × 128 results on the VoxCeleb dataset. Several results of SF2F are shown. SF2F can be genearlized from 64 × 64 pixel reconstruction to higher resolutions. Our method works for various lengths of input audio.
1 Qualitative Results
In the main paper, we compare the 64 × 64 face images generated by SF2F and voice2face [1]. In this section, we compare the 128 × 128 face images reconstructed by both models. As the original voice2face [1, 2] is only trained to generate 64 × 64 images, we compare SF2F and voice2face trained on HQ-VoxCeleb. For the sake of fairness, both models are trained until convergence, and checkpoints with the best L1 similarity is used for inference. As shown in Figure 1, although voice2face can capture attributes such as gender, SF2F generates images with much more accurate facial features and face shape. The pose, expression, and lighting over the faces from SF2F are generally more stable and consistent than the face images from voice2face. In group (f), for example, SF2F predicts a face almost identical to the ground truth, when the corresponding output from voice2face is hardly recognizable. This proves our model design enables more accurate information flow from the speech domain to the face domain.
| Ground Truth (for reference) |
SF2F |
voice2face |
Ground Truth (for reference) |
SF2F |
voice2face |
||
| (a) |  |
 |
 |
(e) |  |
 |
 |
| Input speech |
|||||||
| (b) |  |
 |
 |
(f) |  |
 |
 |
| Input speech |
|||||||
| (c) |  |
 |
 |
(g) |  |
 |
 |
| Input speech |
|||||||
| (d) |  |
 |
 |
(h) |  |
 |
 |
| Input speech |
|||||||
Figure 1: Examples of 128 × 128 generated images using SF2F and voice2face.
2 Data Quality Enhancement
2.1 HQ-VoxCeleb Dataset
As an overview of the HQ-VoxCeleb dataset is presented in the main paper, in this section, we elaborate on the standards and process in our data enhancement scheme. As demonstrated in Figure 2, the poor quality of training dataset for speech2face is one of the major factors hindering the improvement of speech2face performance. To eliminate the negative impact of the training dataset, we carefully design and build a new high-quality face database on top of VoxCeleb dataset, such that face images associated with the celebrities are all at reasonable quality.
|
HQ-VoxCeleb |
Filtered VGGFace |
Problems with Filtered VGGFace
|
||||||
 |
 |
 |
 |
|
||||
 |
 |
 |
 |
|
||||
 |
 |
 |
 |
|
||||
 |
 |
 |
 |
|
||||
 |
 |
 |
 |
|
||||
 |
 |
 |
 |
|
||||
 |
 |
 |
 |
|
||||
 |
 |
 |
 |
|
||||
Figure 2: The quality variance of the original manually filtered VGGFace dataset (on the right of the figure) [3] diverts the efforts of face generator model to the normalization of the faces. By filtering and correcting the face database (on the left), the computer vision models are expected to focus more on the construction of mapping between vocal features and physical facial features.
To fulfill the vision of data quality, we set a number of general guidelines over the face images as the underlying measurement on quality, as follows:
- Face angle between human’s facial plane and the photo imaging plane is no larger than 5°;
- Lighting condition on the face is generally uniform, without any obvious shadow and sharp illumination change;
- Expression on the human faces is generally neutral, while minor smile expression is also acceptable;
- Background does not contain irrelevant information in the image, and completely void background in white is preferred.
To fully meet the standards as listed above, we adopt the following methodology to build the enhanced HQ-VoxCeleb dataset for our speech2face model training.
Data Collection. We collect 300 in-the-wild images for each of the 7,363 individuals in VoxCeleb dataset, by crawling images of the celebrities on the Internet. The visual qualities of the retrieved images are highly diverse. The resolution of the images, for example, ranges from 47 × 59 to 6245 × 8093 in pixels. Moreover, some of the images cover the full body of the celebrity of interest, while other images only include the face of the target individual. It is, therefore, necessary to apply pre-processing and filtering operations to ensure 1) the variance of the image quality is reasonably small; and 2) all the images are centered at the face of the target individuals.
Machine Filtering. To filter out unqualified images from the massive in-the-wild images, we deploy an automated filtering module, together with a suite of concrete selection rules, to eliminate images at poor quality, before dispatching the images for human filtering. In the filtering module, the algorithm first detects the landmarks from the raw face images. Based on the output landmarks of the faces, the algorithm identifies poorly posed faces, if the landmarks from left/right sides cannot be well aligned. Low-resolution face images with distance between pupils covers fewer than 30 pixels are also removed. Finally, a pre-trained CNN classifier [4] is deployed to infer the emotion of the individual in the image, such that faces not recognized as "neutral” emotion are also removed from the dataset.
Image Processing. Given the face images passing the first round machine filtering, we apply a two-step image processing, namely face alignment and image segmentation. In the first step of face alignment, the images are rotated and cropped to make sure both the pupils of the faces in all these images are always at the same coordinates. In the second step of image segmentation, we apply a pyramid scene parsing network [5] pre-trained on Pascal VOC 2012 dataset [6] to split the target individual from the background in the image. The background is then refilled with white pixels. Note that the second step is helpful because irrelevant noise in the background may potentially confuse the generation model.
Human Filtering. To guarantee the final quality of the images in HQ-VoxCeleb dataset, human workers are employed to select 1 to 7 images at best qualities for each celebrity identity. Only celebrities with at least 1 qualified face image are kept in the final dataset.
2.2 Comparison with Existing Datasets
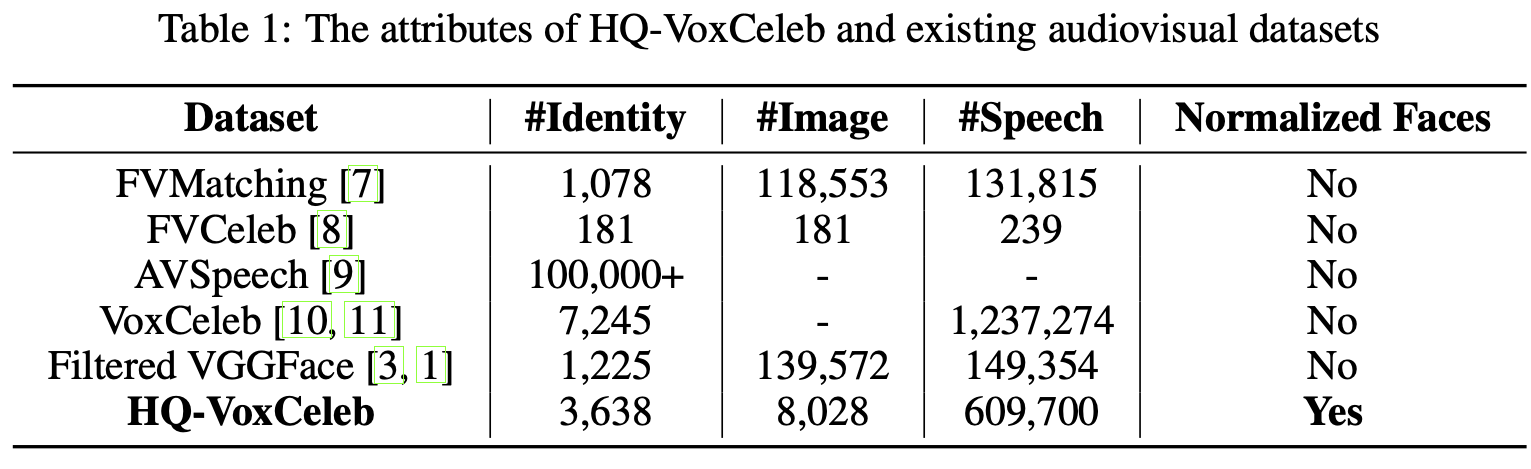
In the main paper, we summarize the statistics of the result dataset after the adoption of the processing steps above. In this section, we compare HQ-VoxCeleb with existing audiovisual datasets [7, 8, 9, 10, 11] in terms of data quality and its impact to model training, in order to justify the contribution of HQ-VoxCeleb. Table 1 shows the attributes of existing audiovisual datasets.
Existing datasets, including VoxCeleb [11, 10] and AVSpeech [9], contain a massive number of pairwise data of human speech and face images. However, the existing datasets are constructed by cropping face images and speech audio from in-the-wild online data, and the face images thus vary hugely in pose, lighting, and emotion, which makes the existing datasets unfit for end-to-end learning of speech-to-face algorithms. To the highest image quality of existing datasets, Wen et al. [1] use the intersection of the filtered VGGFace [7] and VoxCeleb with the common identities. However, as shown in Fig. 2, the filtered VGGFace cannot meet the quality standards defined in section 2.1. Moreover, HQ-VoxCeleb has triple as many identities as filtered VGGFace as shown in Table 1. In conclusion, the high quality and reasonable amount of data make HQ-VoxCeleb the most suitable dataset for speech2face tasks.
3 Additional Experimental Results
3.1 Ablation Study
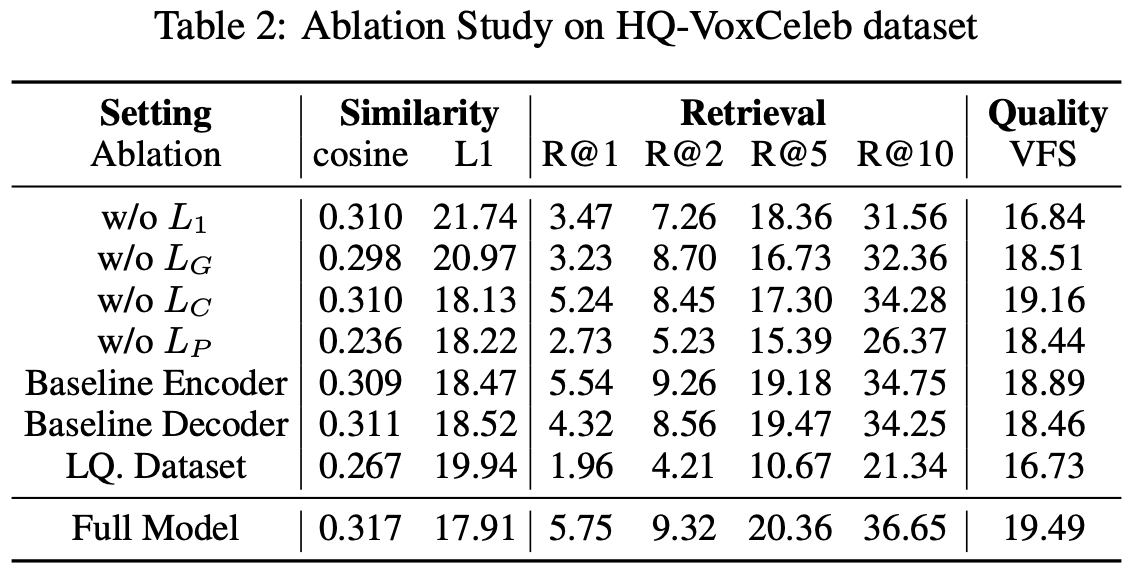
In this section, we focus on the effectiveness evaluation over the model components, loss functions, and dataset used in our SF2F model. The ablated models are trained to generate 64 × 64 images, with all the results are summarized in Table 2. When removing any of the four loss functions in {L1, LG, LC , LP}, the performance of SF2F drops accordingly. This shows it is necessary to include all these components to ensure the learning procedure of the model is well balanced. 1D-CNN encoder is used in the baseline approach [1], while SF2F employs 1D-Inception encoder instead. We report the performance of SF2F by replacing our encoder with 1D-CNN, referred to as Baseline Encoder in Table 2. This replacement causes a significant drop of the performance on all metrics. Similarly, by adopting the deconvolution-based decoder used in [1, 12] instead of the upsampling-and-convolution-based decoder in SF2F, referred as Baseline Decoder in Table 2, we observe a slight yet consistent performance drop. The impact of data quality is also evaluated, by training the SF2F model with the manually filtered version of VGGFace dataset [3] instead of HQ-VoxCeleb, by including overlap celebrity individuals included in both datasets. Poor data quality obviously leads to a huge performance plunge, which further justifies the importance of training data quality enhancement.
3.2 Performance on Filtered VGGFace
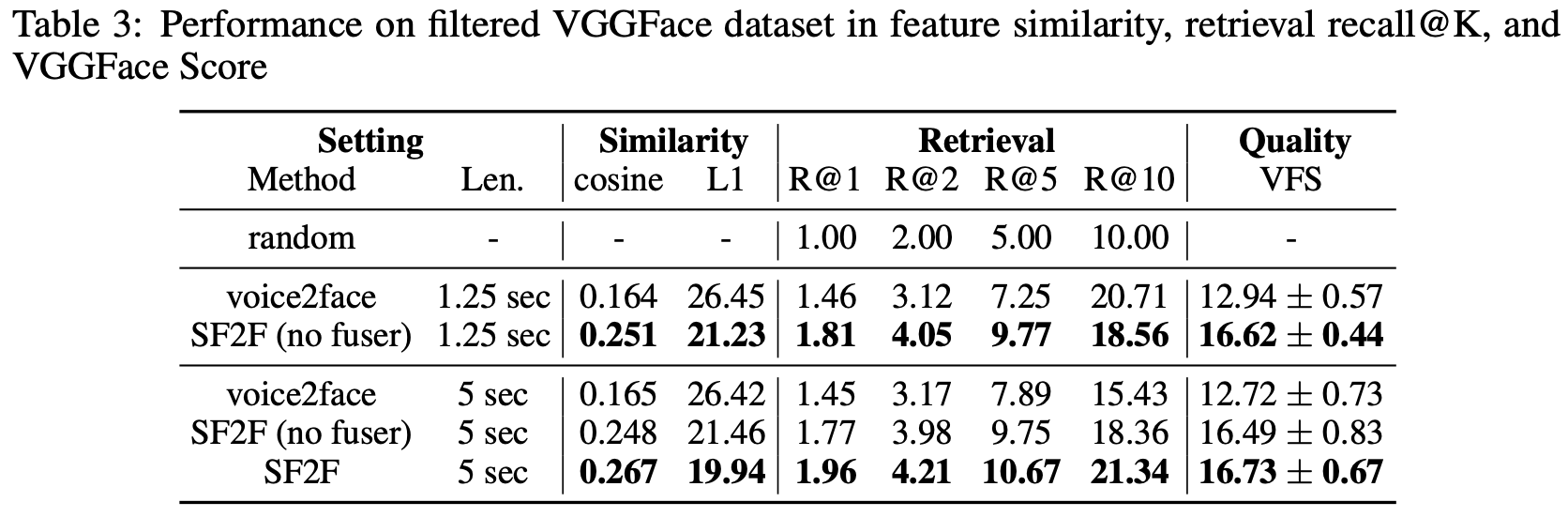
We also compare the performance of SF2F and voice2face [1] on the filtered VGGFace dataset [3], to evaluate how SF2F functions under less controlled conditions. To make a fair comparison, we train both models with filtered VGGFace dataset. Both voice2face and our SF2F are trained to generate images with 64 × 64 pixels, and evaluated with 1.25 seconds and 5 seconds of human speech clips. As is presented in Table 3, SF2F outperforms voice2face by a large margin on all metrics. By deploying fuser in SF2F, the maximal recall@10 reaches 21.34%, significantly outperforming voice2face.
4 Model Details
4.1 Voice Encoder
We use a 1D-CNN composed of several 1D Inception modules [13] to process mel-spectrogram. The voice encoder module converts each short input speech segment into a predicted facial feature embedding. The architecture of the 1D Inception module and the voice encoder is summarized in Table 4. The Inception module models various ranges of short-term mel-spectrogram dependency, and enables more accurate information flow from voice domain to image domain, compared to plain single-kernel-size CNN used in [1].

4.2 Face Decoder
4.2.1 Single-resolution Decoder
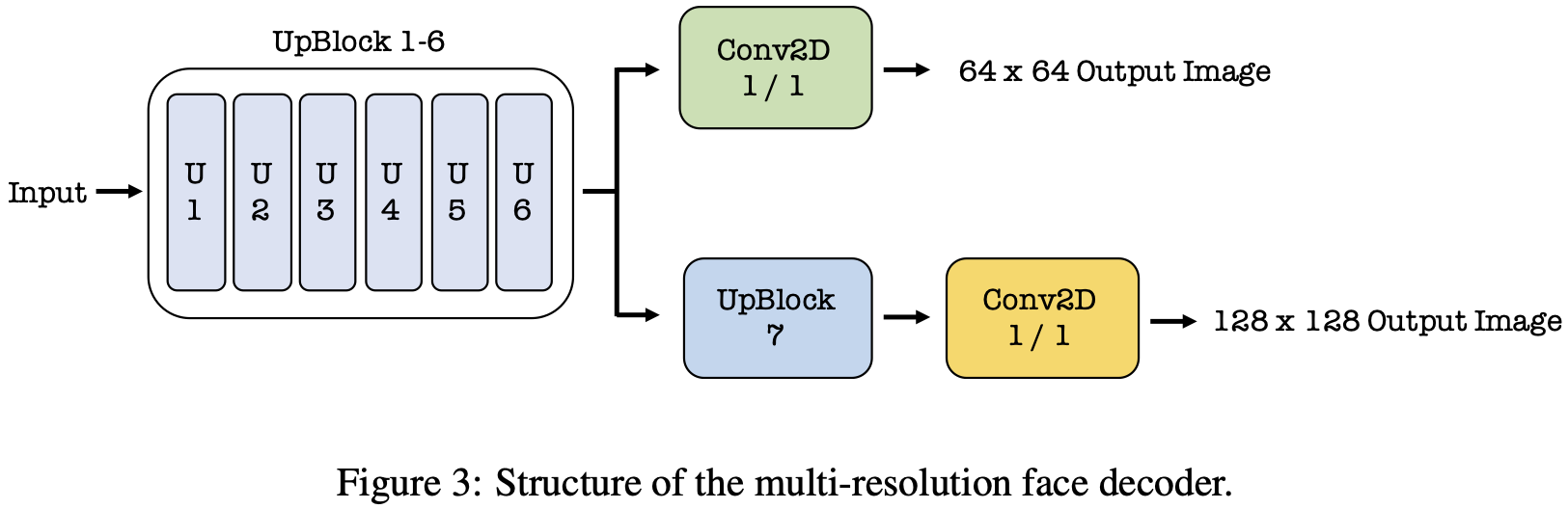
The face decoder reconstructs the target individual’s face image based on the embeddings extracted from the individual’s speech segments. The architectures of the upsampling block (UpBlock) and the face decoder are summarized in Table 5. We show the structure of the face decoder that generates 64 × 64 images, and the face decoder generates 128 × 128 images can be built by adding an UpBlock 7 after UpBlock 6. Our empirical evaluations prove that our decoder based on upsampling and convolution leads to better performance in all the metrics compared to the deconvolution-based decoder employed in existing studies [12] and [1].

4.2.2 Multi-resolution Decoder
Inspired by [14], the multi-resolution decoder is optimized to generate images at both low resolution and high resolution, which is shown in Figure 3. With the multi-resolution approach, the decoder learns to model the multiple target domain distributions of different scales, which helps to overcome the difficulty of generating high-resolution images.
4.3 Discriminators
The network structure of image discriminator Dreal and identity classifier Did is described in Table 6. Both networks are convolutional neural networks, followed by fully connected networks. In Table 6, we demonstrate the structure of discriminators for 64 × 64 images, and the discriminator of 128 × 128 images can be simply implemented by adding another convolution layer before average pooling layer.

4.4 Complexity Analysis of SF2F model
Shown in Table 7 is the time and space complexity of each component of SF2F model, where t stands for the length of the input audio and w stands for the width of the output face image. The time complexity of convolution and attention is Ω(1) regardless of the input length. The space complexity of 1D convolution is O(t) and space complexity of attention is O(t2).

5 Implementation Details
5.1 Training
We train all our SF2F models on 1 NVIDIA V100 GPU with 32 GB memory; SF2F is implemented with PyTorch [15]. The encoder-decoder training takes 120,000 iterations, and the fuser training takes 360 iterations. The training of 64 × 64 models takes about 18 hours, and the training of 128 × 128 models takes about 32 hours. The model is trained only once in each experiment.
5.2 Evaluation
Evaluation is conducted on the same GPU machine. The details of the implementation are provided in this part of the section.
Ground Truth Embedding Matrix. As mentioned in the main paper, the ground truth embedding matrix `U = {u_1, u_2, ..., u_N}` extracted by FaceNet [16] is used for similarity metric and retrieval metric. Given that one identity is often associated with multiple, i.e., K, face images in both datasets, for an identity of index n, the ground truth embedding is computed by `sum_(j=1)^K u_(nj)/K`. The embedding `u_n` is normalized as `u_n = frac{u_n}{max(||u_n||_2, ε)}` , because the embeddings extracted by FaceNet are also L2 normalized. Building embedding matrix with all the image data helps remove variance in data. This makes the evaluation results fair and stable.
Evaluation Runs. In each experiment, we randomly crop 10 pieces of audio with desired length for each identity in the evaluation dataset. With the data above, each experiment is evaluated ten times, the mean of each metric is calculated based on the outcomes of all these ten evaluation runs. We additionally report the variance of VGGFace Score.
5.3 Hyperparameter
The hyperparameters for SF2F’s model training are listed in Table 8. The detailed configuration of SF2F’s network is available in Section 4 as well as the main paper.
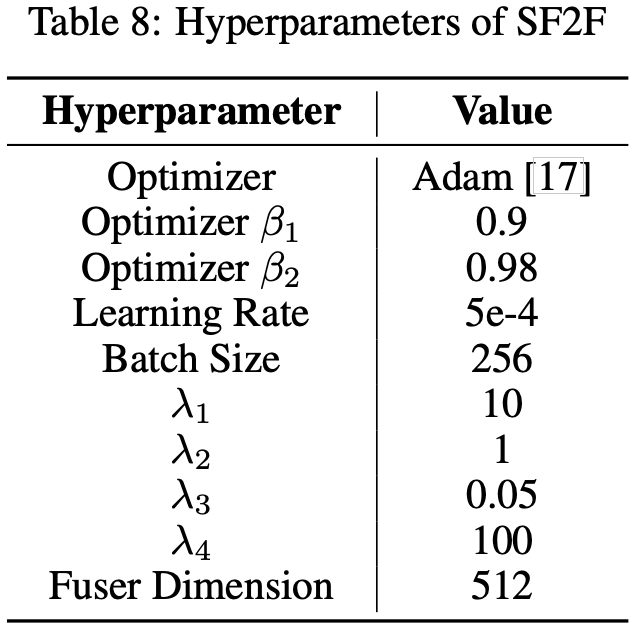
Hyperparameters are carefully tuned. As the training is time-consuming and the hyperparameter space is large, it is difficult to apply grid search directly. We adopt other methods for parameter tuning instead.
We first train a SF2F model with λ1, λ2, λ3 = 1 and λ4 = 0, we adjust the parameters λ1 and λ3 and find that increasing the Image Reconstruction Loss weight λ1 and decreasing the Auxiliary Classifier Loss weight λ3 both improve the model performance. We adjust λ1 and λ3 gradually and find out the model achieves the best performance when λ1 = 10 and λ3 = 0.05. Afterward, we apply Perceptual Loss to our model training with initial weight λ4 = 1. We find increasing λ4 improves SF2F’s performance, which is because the original scale of Perceptual Loss is much smaller than the scale of the other three losses. We gradually increase λ4 until we observe SF2F achieving the best performance when λ4 = 100. Therefore, λ1, λ2, λ3, λ4 are set at 10, 1, 0.05 and 100, respectively.
Afterwards, we apply a grid search over learning rate and batch size. We test with different values, which are listed in Table 9 with optimal values singled out in the last column.
The hyperparameters above are determined by tuning a 64 × 64 SF2F model with HQ-VoxCeleb dataset, and we find this hyperparameter configuration works well with 128 × 128 SF2F model. With this hyperparameter configuration, SF2F outperforms voice2face on filtered VGGFace dataset.

Consequently, we opt to skip further hyperparameter tuning on filtered VGGFace. The total cost of hyperparameter tuning is around 558 GPU hours on V100.
References
- Yandong Wen, Bhiksha Raj, and Rita Singh.: Face reconstruction from voice using generative adversarial networks. In Advances in Neural Information Processing Systems, pages 5266–5275, 2019.
- Yandong Wen, Bhiksha Raj, and Rita Singh.: Implementation of reconstructing faces from voices paper. https://github.com/cmu-mlsp/reconstructing_faces_from_voices. Accessed: 2020-5-29.
- Omkar M Parkhi, Andrea Vedaldi, and Andrew Zisserman.: Deep face recognition. 2015.
- Octavio Arriaga, Matias Valdenegro-Toro, and Paul Plöger.: Real-time convolutional neural networks for emotion and gender classification. arXiv preprint arXiv:1710.07557, 2017.
- Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia.: Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2881–2890, 2017.
- M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman.: The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html.
- Shota Horiguchi, Naoyuki Kanda, and Kenji Nagamatsu.: Face-voice matching using cross-modal embeddings. In Proceedings of the 26th ACM international conference on Multimedia, pages 1011–1019, 2018.
- Changil Kim, Hijung Valentina Shin, Tae-Hyun Oh, Alexandre Kaspar, Mohamed Elgharib, and Wojciech Matusik.: On learning associations of faces and voices. In Asian Conference on Computer Vision,, pages 276–292. Springer, 2018.
- Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T Freeman, and Michael Rubinstein.: Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. arXiv preprint arXiv:1804.03619, 2018.
- Arsha Nagrani, Joon Son Chung, and Andrew Zisserman: Voxceleb: A large-scale speaker identification dataset. In Interspeech, pages 2616–2620, 2017.
- Joon Son Chung, Arsha Nagrani, and Andrew Zisserman.: Voxceleb2: Deep speaker recognition. In Interspeech, pages 1086–1090, 2018.
- Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William T. Freeman, Michael Rubinstein, and Wojciech Matusik.: Speech2face: Learning the face behind a voice. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich.: Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2015.
- Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas.: Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE transactions on pattern analysis and machine intelligence, 41(8):1947–1962, 2018.
- Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al.: Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems, pages 8024–8035, 2019.
- Florian Schroff, Dmitry Kalenichenko, and James Philbin.: Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 815–823, 2015.
- Diederik P. Kingma and Jimmy Ba.: Adam: A method for stochastic optimization. In ICLR, 2015.